爬虫批量爬取抖音(快手短爬取经验分享)
爬虫批量爬取抖音(快手短爬取经验分享)保存后就可以了,fiddler就可以抓到app的数据了,打开快手 刷新,可以看到有很多http请求进来,一般接口地址之类的很明显的,可以看到是json类型的安装证书之后,在WiFi设置 修改网络 手动指定http代理首先,打开fiddler,fiddler作为http/https 抓包神器,这里就不多介绍。 配置允许https配置允许远程连接 也就是打开http代理电脑ip: 192.168.1.110 然后 确保手机和电脑是在一个局域网下,可以通信。由于我这边没有安卓手机,就用了安卓模拟器代替,效果一样的。打开手机浏览器,输入192.168.1.110:8888,也就是设置的代理地址,安装证书之后才能抓包

作者:冰蓝的天空
原文:http://www.cnblogs.com/binglansky/p/8483096.html
-
环境: python 2.7 win10
-
工具:fiddler postman 安卓模拟器
首先,打开fiddler,fiddler作为http/https 抓包神器,这里就不多介绍。 配置允许https
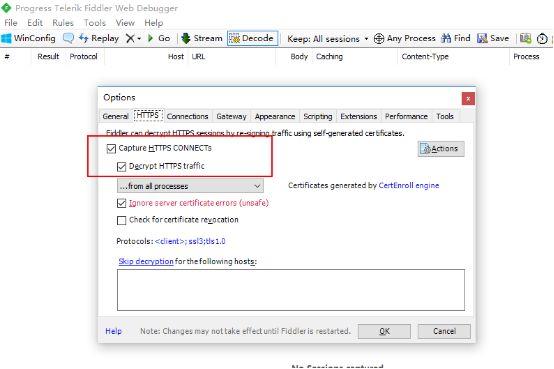
配置允许远程连接 也就是打开http代理

电脑ip: 192.168.1.110 然后 确保手机和电脑是在一个局域网下,可以通信。由于我这边没有安卓手机,就用了安卓模拟器代替,效果一样的。打开手机浏览器,输入192.168.1.110:8888,也就是设置的代理地址,安装证书之后才能抓包

安装证书之后,在WiFi设置 修改网络 手动指定http代理

保存后就可以了,fiddler就可以抓到app的数据了,打开快手 刷新,可以看到有很多http请求进来,一般接口地址之类的很明显的,可以看到是json类型的

http post请求,返回数据是json ,展开后发现一共是20条视频信息,先确保是否正确,找一个视频链接看下。

ok 是可以播放的 很干净也没有水印。那就打开postman 来测试,form-data 方式提交则报错

那换raw 这种

报错信息不一样了,试试加上headers

nice 成功返回数据,我又多试几次,发现每次返回结果不一样,都是20个视频,刚才其中post参数中有个page=1 这样一直都是第一页就像一直在手机上不往下翻了就开始一直刷新那样,反正也无所谓,只要返回数据 不重复就好。
下面就开始上代码
-
# -*-coding:utf-8-*- -
# author : Corleone -
import urllib2 urllib -
import json os re socket time sys -
import Queue -
import threading -
import logging -
# 日志模块 -
logger = logging.getLogger("AppName") -
formatter = logging.Formatter('%(asctime)s %(levelname)-5s: %(message)s') -
console_handler = logging.StreamHandler(sys.stdout) -
console_handler.formatter = formatter -
logger.addHandler(console_handler) -
logger.setLevel(logging.INFO) -
video_q = Queue.Queue # 视频队列 -
def get_video: -
url = "http://101.251.217.210/rest/n/feed/hot?app=0&lon=121.372027&c=BOYA_BAIDU_PINZHUAN&sys=ANDROID_4.1.2&mod=HUAWEI(HUAWEI C8813Q)&did=ANDROID_e0e0ef947bbbc243&ver=5.4&net=WIFI&country_code=cn&iuid=&appver=5.4.7.5559&max_memory=128&oc=BOYA_BAIDU_PINZHUAN&ftt=&ud=0&language=zh-cn&lat=31.319303 " -
data = { -
'type': 7 -
'page': 2 -
'coldStart': 'false' -
'count': 20 -
'pv': 'false' -
'id': 5 -
'refreshTimes': 4 -
'pcursor': 1 -
'os': 'android' -
'client_key': '3c2cd3f3' -
'sig': '22769f2f5c0045381203fc57d1b5ad9b' -
} -
req = urllib2.Request(url) -
req.add_header("User-Agent" "kwai-android") -
req.add_header("Content-Type" "application/x-www-form-urlencoded") -
params = urllib.urlencode(data) -
try: -
html = urllib2.urlopen(req params).read -
except urllib2.URLError: -
logger.warning(u"网络不稳定 正在重试访问") -
html = urllib2.urlopen(req params).read -
result = json.loads(html) -
reg = re.compile(u"[u4e00-u9fa5] ") # 只匹配中文 -
for x in result['feeds']: -
try: -
title = x['caption'].replace("n" "") -
name = " ".join(reg.findall(title)) -
video_q.put([name x['photo_id'] x['main_mv_urls'][0]['url']]) -
except KeyError: -
pass -
def download(video_q): -
path = u"D:快手" -
while True: -
data = video_q.get -
name = data[0].replace("n" "") -
id = data[1] -
url = data[2] -
file = os.path.join(path name ".mp4") -
logger.info(u"正在下载:%s" %name) -
try: -
urllib.urlretrieve(url file) -
except IOError: -
file = os.path.join(path u"神经病呀" '%s.mp4') %id -
try: -
urllib.urlretrieve(url file) -
except (socket.error urllib.ContentTooShortError): -
logger.warning(u"请求被断开,休眠2秒") -
time.sleep(2) -
urllib.urlretrieve(url file) -
logger.info(u"下载完成:%s" % name) -
video_q.task_done -
def main: -
# 使用帮助 -
try: -
threads = int(sys.argv[1]) -
except (IndexError ValueError): -
print u"n用法: " sys.argv[0] u" [线程数:10] n" -
print u"例如:" sys.argv[0] " 10" u" 爬取视频 开启10个线程 每天爬取一次 一次2000个视频左右(空格隔开)" -
return False -
# 判断目录 -
if os.path.exists(u'D:快手') == False: -
os.makedirs(u'D:快手') -
# 解析网页 -
logger.info(u"正在爬取网页") -
for x in range(1 100): -
logger.info(u"第 %s 次请求" % x) -
get_video -
num = video_q.qsize -
logger.info(u"共 %s 视频" %num) -
# 多线程下载 -
for y in range(threads): -
t = threading.Thread(target=download args=(video_q )) -
t.setDaemon(True) -
t.start -
video_q.join -
logger.info(u"-----------全部已经爬取完成---------------") -
main
下面测试

多线程下载 每次下载2000 个视频左右 默认下载到D:快手

总结:其实我这次爬的快手有点投机取巧了,因为post过去的参数 sign 是签名 的确是有加密的,只所以还能返回数据。
那是因为我每次都是请求的一样的链接 page=1 都是第一页的 当我改成2的时候,就验签失败了。然而,它刚好这样也能返回不同的数据,虽然达到了效果,但却没有能破解他的加密算法。。。
最后放上我的github地址 : https://github.com/binglansky/spider
题图:pexels,CC0 授权。



