大数据应用分析与建模(大数据建模与分析挖掘应用实践)
大数据应用分析与建模(大数据建模与分析挖掘应用实践)地点:北京 上海 深圳 杭州 成都 苏州 珠海张老师:阿里大数据高级专家,国内资深的Spark、Hadoop技术专家、虚拟化专家,对HDFS、MapReduce、HBase、Hive、Mahout、Storm、spark和openTSDB等Hadoop生态系统中的技术进行了多年的深入的研究,更主要的是这些技术在大量的实际项目中得到广泛的应用,因此在Hadoop开发和运维方面积累了丰富的项目实施经验。近年主要典型的项目有:某电信集团网络优化、中国移动某省移动公司请账单系统和某省移动详单实时查询系统、中国银联大数据数据票据详单平台、某大型银行大数据记录系统、某大型通信运营商全国用户上网记录、某省交通部门违章系统、某区域医疗大数据应用项目、互联网公共数据大云(DAAS)和构建游戏云(Web Game Daas)平台项目等。学员需要准备的电脑最好是i5及以上CPU,4GB及以上内存,硬盘空间预留5
大数据建模与分析挖掘技术已经逐步地应用到新兴互联网企业(如电子商务网站、搜索引擎、社交网站、互联网广告服务提供商等)、银行金融证券企业、电信运营等行业,给这些行业带来了一定的数据价值增值作用。
本次课程面向有一定的数据分析挖掘算法基础的工程师,带大家实践大数据分析挖掘平台的项目训练,系统地讲解数据准备、数据建模、挖掘模型建立、大数据分析与挖掘算法应用在业务模型中,结合主流的Hadoop与Spark大数据分析平台架构,实现项目训练。
结合业界使用最广泛的主流大数据平台技术,重点剖析基于大数据分析算法与BI技术应用,包括分类算法、聚类算法、预测分析算法、推荐分析模型等在业务中的实践应用,并根据讲师给定的数据集,实现两个基本的日志数据分析挖掘系统,以及电商(或内容)推荐系统引擎。
本课程基本的实践环境是Linux集群,JDK1.8, Hadoop 2.7.*,Spark 2.1.*。
学员需要准备的电脑最好是i5及以上CPU,4GB及以上内存,硬盘空间预留50GB(可用移动硬盘),基本的大数据分析平台所依赖的软件包和依赖库等,讲师已经提前部署在虚拟机镜像(VMware镜像),学员根据讲师的操作任务进行实践。
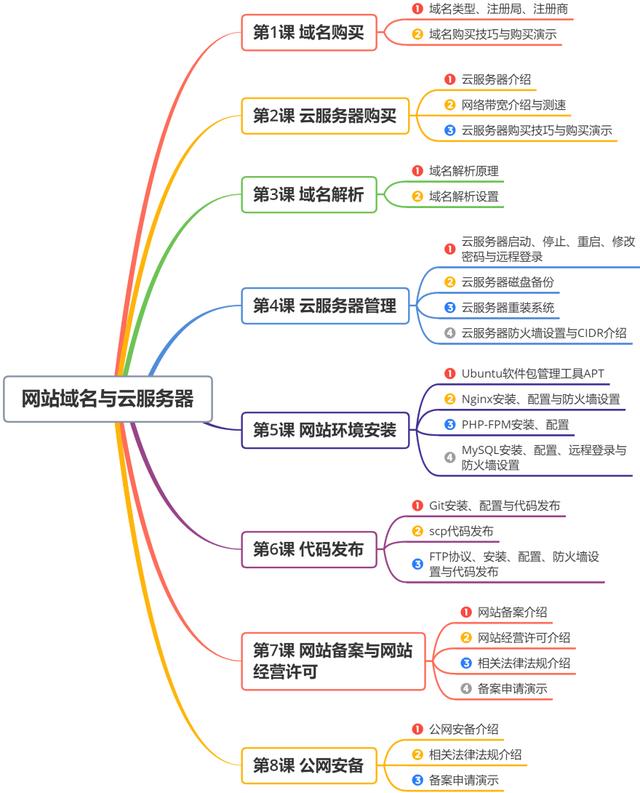
详细大纲




周老师,男,中国科学院通信与信息系统专业博士。北京邮电大学移动互联网与信息化实验室特聘研究员、对外经贸大学信息学院特聘兼职教师、中国移动集团高级培训讲师,长期从事大数据、4G、移动互联网安全、管理及大数据精确营销等研究方向。国内顶级信息系统架构师,金牌讲师,技术顾问,移动开发专家。拥有丰富的通信信息系统设计、开发经验及培训行业经验,先后为全国超过15家省移动公司,超过30家地市移动公司有过项目开发合作及授课,担任多个大型通信项目的总师。
张老师:阿里大数据高级专家,国内资深的Spark、Hadoop技术专家、虚拟化专家,对HDFS、MapReduce、HBase、Hive、Mahout、Storm、spark和openTSDB等Hadoop生态系统中的技术进行了多年的深入的研究,更主要的是这些技术在大量的实际项目中得到广泛的应用,因此在Hadoop开发和运维方面积累了丰富的项目实施经验。近年主要典型的项目有:某电信集团网络优化、中国移动某省移动公司请账单系统和某省移动详单实时查询系统、中国银联大数据数据票据详单平台、某大型银行大数据记录系统、某大型通信运营商全国用户上网记录、某省交通部门违章系统、某区域医疗大数据应用项目、互联网公共数据大云(DAAS)和构建游戏云(Web Game Daas)平台项目等。
地点:北京 上海 深圳 杭州 成都 苏州 珠海
时间:2019.3月——12月期间(具体请私信)