对常用的数据库进行分析归纳总结,详解一张历史数据库性能的关键表--dba
对常用的数据库进行分析归纳总结,详解一张历史数据库性能的关键表--dba在这里指定的是top 2 event,并且注掉了采样时间以观察所有采样点的情况。如果数据量较多,您也可以通过开启sample_time的注释来观察某个时间段的情况。注意最后一列session_count指的是该采样点上的等待该event的session数量。注意: 观察以上的输出有无断档,比如某些时间没有采样。SQL> create table m_ash as select * from dba_hist_active_sess_history where SAMPLE_TIME between TO_TIMESTAMP ('<time_begin>' 'YYYY-MM-DD HH24:MI:SS') and TO_TIMESTAMP ('<time_end>' 'YYYY-MM-DD HH24:MI:SS'); 2. 查看ASH时间范围:为了加快速
概述在很多情况下,当数据库发生性能问题的时候,我们并没有机会来收集足够的诊断信息,比如system state dump或者hang analyze,甚至问题发生的时候DBA根本不在场。这给我们诊断问题带来很大的困难。那么在这种情况下,我们是否能在事后收集一些信息来分析问题的原因呢?
今天主要介绍一种通过dba_hist_active_sess_history的数据来分析问题的一种方法,虽然通过awr也可以获取相关信息。
思路
AWR和ASH采样机制,有一个视图gv$active_session_history会每秒钟将数据库所有节点的Active Session采样一次,而dba_hist_active_sess_history则会将gv$active_session_history里的数据每10秒采样一次并持久化保存。基于这个特征,可以通过分析dba_hist_active_sess_history的Session采样情况,来定位问题发生的准确时间范围,并且可以观察每个采样点的top event和top holder。
1. Dump出问题期间的ASH数据:
基于dba_hist_active_sess_history创建一个新表m_ash
SQL> create table m_ash as select * from dba_hist_active_sess_history where SAMPLE_TIME between TO_TIMESTAMP ('<time_begin>' 'YYYY-MM-DD HH24:MI:SS') and TO_TIMESTAMP ('<time_end>' 'YYYY-MM-DD HH24:MI:SS');

2. 查看ASH时间范围:
为了加快速度这里采用了并行查询。
alter session set nls_timestamp_format='yyyy-mm-dd hh24:mi:ss.ff'; select /* parallel 8 */ t.dbid t.instance_number min(sample_time) max(sample_time) count(*) session_count from m_ash t group by t.dbid t.instance_number order by dbid instance_number;
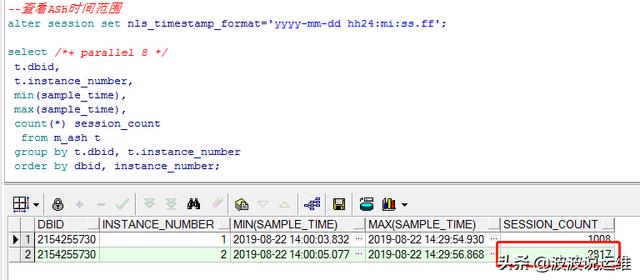
从以上输出可知该数据库共2个节点,采样时间共30分钟,节点2的采样比节点1要多很多,问题可能发生在节点2上。
3. 确认问题发生的精确时间范围:
select /* parallel 8 */ dbid instance_number sample_id sample_time count(*) session_count from m_ash t group by dbid instance_number sample_id sample_time order by dbid instance_number sample_time;


注意观察以上输出的每个采样点的active session的数量,数量突然变多往往意味着问题发生了。
注意: 观察以上的输出有无断档,比如某些时间没有采样。
4. 确定每个采样点的top n event:
在这里指定的是top 2 event,并且注掉了采样时间以观察所有采样点的情况。如果数据量较多,您也可以通过开启sample_time的注释来观察某个时间段的情况。注意最后一列session_count指的是该采样点上的等待该event的session数量。
select t.dbid t.sample_id t.sample_time t.instance_number t.event t.session_state t.c session_count from (select t.* rank() over(partition by dbid instance_number sample_time order by c desc) r from (select /* parallel 8 */ t.* count(*) over(partition by dbid instance_number sample_time event) c row_number() over(partition by dbid instance_number sample_time event order by 1) r1 from m_ash t /*where sample_time > to_timestamp('2019-08-22 13:59:00' 'yyyy-mm-dd hh24:mi:ss') and sample_time < to_timestamp('2019-08-22 14:10:00' 'yyyy-mm-dd hh24:mi:ss')*/ ) t where r1 = 1) t where r < 3 order by session_count desc dbid instance_number sample_time r;


从以上输出我们可以发现问题期间最严重的等待为gc buffer busy acquire,高峰期等待该event的session数达到了16个,其次为db file sequential read,高峰期session为5个。
5. 观察每个采样点的等待链
其原理为通过dba_hist_active_sess_history. blocking_session记录的holder来通过connect by级联查询,找出最终的holder. 在RAC环境中,每个节点的ASH采样的时间很多情况下并不是一致的,因此可以通过将本SQL的第二段注释的sample_time稍作修改让不同节点相差1秒的采样时间可以比较(注意最好也将partition by中的sample_time做相应修改)。该输出中isleaf=1的都是最终holder,而iscycle=1的代表死锁了(也就是在同一个采样点中a等b,b等c,而c又等a,这种情况如果持续发生,那么尤其值得关注)。采用如下查询能观察到阻塞链。
select /* parallel 8 */ level lv connect_by_isleaf isleaf connect_by_iscycle iscycle t.dbid t.sample_id t.sample_time t.instance_number t.session_id t.sql_id t.session_type t.event t.session_state t.blocking_inst_id t.blocking_session t.blocking_session_status from m_ash t /*where sample_time > to_timestamp('2019-08-22 13:55:00' 'yyyy-mm-dd hh24:mi:ss') and sample_time < to_timestamp('2019-08-22 14:10:00' 'yyyy-mm-dd hh24:mi:ss')*/ start with blocking_session is not null connect by nocycle prior dbid = dbid and prior sample_time = sample_time /*and ((prior sample_time) - sample_time between interval '-1' second and interval '1' second)*/ and prior blocking_inst_id = instance_number and prior blocking_session = session_id and prior blocking_session_serial# = session_serial#;

从上面的输出可见,在相同的采样点上(2019-08-22 14:00:05.077),节点1 session 165、319、396、473、625、857全部在等待gc buffer busy acquire,其被节点2 session 1090阻塞。
6. 基于第5步的原理来找出每个采样点的最终top holder:
比如如下SQL列出了每个采样点top 2的blocker session,并且计算了其最终阻塞的session数(参考blocking_session_count)
select t.lv t.iscycle t.dbid t.sample_id t.sample_time t.instance_number t.session_id t.sql_id t.session_type t.event t.seq# t.session_state t.blocking_inst_id t.blocking_session t.blocking_session_status t.c blocking_session_count from (select t.* row_number() over(partition by dbid instance_number sample_time order by c desc) r from (select t.* count(*) over(partition by dbid instance_number sample_time session_id) c row_number() over(partition by dbid instance_number sample_time session_id order by 1) r1 from (select /* parallel 8 */ level lv connect_by_isleaf isleaf connect_by_iscycle iscycle t.* from m_ash t /*where sample_time > to_timestamp('2013-11-17 13:55:00' 'yyyy-mm-dd hh24:mi:ss') and sample_time < to_timestamp('2013-11-17 14:10:00' 'yyyy-mm-dd hh24:mi:ss')*/ start with blocking_session is not null connect by nocycle prior dbid = dbid and prior sample_time = sample_time /*and ((prior sample_time) - sample_time between interval '-1' second and interval '1' second)*/ and prior blocking_inst_id = instance_number and prior blocking_session = session_id and prior blocking_session_serial# = session_serial#) t where t.isleaf = 1) t where r1 = 1) t where r < 3 order by blocking_session_count desc dbid sample_time r;

注意以上输出,比如第一行,代表在22-AUG-19 02.00.05.077 PM,节点2的session 1090最终阻塞了7个session. 顺着时间往下看,可见节点2存在多个session都堵塞了接近10个session 其中会话10是问题期间最严重的holder,并且它持续等待gc cr block busy,注意观察其seq#会发现该event的seq#在不断变化,表明该session并未完全hang住,涉及sql为4ksvn2rgjnhcm,可以结合Scheduler/MMAN/MMNL的trace以及dba_hist_memory_resize_ops的输出进一步确定问题。
7.查看具体sql信息
select listagg(sql_text ' ') within group (order by piece) from v$sqltext where sql_id = '4ksvn2rgjnhcm' group by sql_id

注意:
1) blocking_session_count 指某一个holder最终阻塞的session数,比如 a <- b<- c (a被b阻塞 b又被c阻塞),只计算c阻塞了1个session,因为中间的b可能在不同的阻塞链中发生重复。
2) 如果最终的holder没有被ash采样(一般因为该holder处于空闲),比如 a<- c 并且b<- c (a被c阻塞,并且b也被c阻塞),但是c没有采样,那么以上脚本无法将c统计到最终holder里,这可能会导致一些遗漏。
3) 注意比较blocking_session_count的数量与第3步查询的每个采样点的总session_count数,如果每个采样点的blocking_session_count数远小于总session_count数,那表明大部分session并未记载holder,因此本查询的结果并不能代表什么。
后面会分享更多devops和DBA方面的内容,感兴趣的朋友可以关注下~




