maxcompute如何存储数据(基于MaxCompute的图计算实践分享-解析图加载过程)
maxcompute如何存储数据(基于MaxCompute的图计算实践分享-解析图加载过程)获取图作业的所有输入表或者分区;我们将图的加载过程实现为一个网络版的MapReduce过程,如下图所示:计算,遍历内存中的点,经过不断的迭代,直至达到迭代终止; Graph 模型有点(vertex)和边(edge)组成,以邻接表的形式进行组织,如下图: 图的原始数据存在于MaxCompute 的表(table)中,每个 table 包含多个记录(record),每个 record 又包含多个列(field),图加载就是将这种形式的数据,转换成 vertex 和 edge的过程。二、图加载阶段
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data,此外,通过Maxcompute及其配套产品,大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
一、前言
MaxCompute Graph 是基于飞天平台实现的面向迭代的图处理框架,为用户提供了类似于 Pregel 的编程接口。MaxCompute Graph(以下简称 Graph )作业包含图加载和计算两个阶段:
-
加载,将存储在表中的数据载入到内存中,以点和边的形式存在;
-
计算,遍历内存中的点,经过不断的迭代,直至达到迭代终止; Graph 模型有点(vertex)和边(edge)组成,以邻接表的形式进行组织,如下图:

图的原始数据存在于MaxCompute 的表(table)中,每个 table 包含多个记录(record),每个 record 又包含多个列(field),图加载就是将这种形式的数据,转换成 vertex 和 edge的过程。
二、图加载阶段
我们将图的加载过程实现为一个网络版的MapReduce过程,如下图所示:
获取图作业的所有输入表或者分区;
拿到输入表或分区下的所有数据文件;
按照指定字节数(块大小)将大文件进行切割,或者小文件合并;
切割后的块或者多个小文件组成的块,就是最终每个worker的输入(split);
额外解释一下第三步的切割(或合并),我们知道表或者分区的数据都是存储在一个或多个文件中的,而文件有大有小。在根据指定的字节数 split size划分块时,我们将大于split size的文件称为大文件,小于split size的小文件。
因此,为了保证每个块字节数基本相等,需要将大文件按照split size切分成小块,具体形式就是有三元组(文件名,起始偏移字节,块长度)表示,文件尾剩余的字节数如果过小,会合并到最后一块中。而对于小文件们,则需要将多个小文件作为一个块,具体形式有多个三元组组成【(文件名,0,文件长度),(文件名,0,文件长度)】,最终块的大小也会受块中小文件的个数限制(保证不会因为过多的小文件导致载入时间过长)。
至此,我们已经将输入划分成了块,假设块的个数为m,根据不同的作业配置,数据并行载入的方式也不相同。
-
默认情况下,我们会创建m个worker(m最多为1000),每个worker按照编号读取对应的块,split和worker对应情况如下:

对于此种情况,worker和split是一对一的关系,worker数由split的个数决定,如果split个数超过1000,则作业会因为worker数超过1000报错。
-
Graph作业同时支持用户手工设置worker数,这时候又会出现一个worker对应零个或多个split的情况。
如果split size比较小,导致split的个数多于设定的worker数,则worker与split的对应关系如下图:

如果split size比较大,导致split的个数少于设定的worker数,则worker与split的对应关系如下图:

因此,用户手工设定 worker 数的情况下,调整split size的大小,有助于提高数据的载入速度。
总结一下,本小节将输入分解成了块,并确定了worker和块之间的关系。不管哪种情况,最终的结果是,一个 worker 会分到零个或多个 split,下面就需要解析一个 worker 是怎么处理 split 的。
2、加载点和边
如上节所述,本节解释单个 worker 处理零个或多个 split 的执行过程。此阶段的实现需要用户实现 GraphLoader 接口,我们会为每个 split 创建单独的 GraphLoader 实例,这个实例负责将 split 中的 record 解释为 vertex 或者 edge。根据此 worker 分到的 split 的个数,分为三种情况:
-
worker 分到零个 split。此种情况下该 worker 无需进入此阶段,直接进入下一阶段。
-
worker 分到一个 split。我们将处理过程用下图表示:

从整体看,GraphLoader 实例会读取 split 中的每个 record,用户可根据此 record 中的语义(如来自哪张表,字段的含义等)解析成 vertex 和(或)edge,解析后的结果以键值对的形式存在,(id vertex)表示为值为 id 的点增加一个 vertex 对象,(id edge)表示为值为id的点增加一个 edge 对象。请注意,vertex 本身也是可以带有 edge 的。
此阶段,可以为单个 id 多次增加 vertex 或 edge 对象,无须关系是否重复,下个阶段会处理这种情况。此过程将 split 中的多个 record,转换成了多个 vertex 或 edge对象。用户可以将其理解成一个 map 过程,将 record 转换成一些(key value),key本身会重复。
-
worker分到多个 split。第二种情况是此第三种情况的特例,表现为一个 worker 多次处理 split 的情况,每次与第二种情况相同。注意,每个 split 有单独的 GraphLoader 实例。
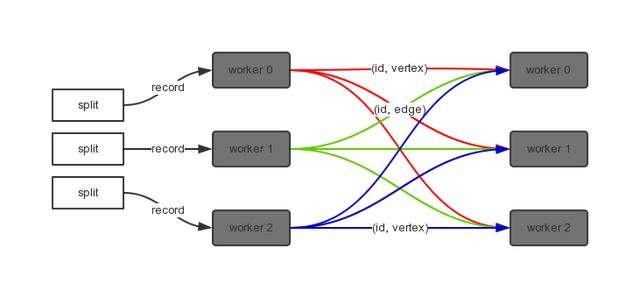
至此,我们已经将 split 中的 record,都转换成了(id vertex)和(id edge)这种形式的键值对,这些键值对是通过用户的 GraphLoader 接口生成的。我们在拿到这些键值对之后,会根据 id 将这些键值对分发到其它的 worker,默认的分发依据是 id 的hash值。同时,每个 worker 在接收到这些键值对后,会根据 id 分组,将相同 id的 vertex 和 edge 组织起来,具体组织形式见下图:

也就是组织成 key -> values 的形式,类似于 reduce 的输入形式,但不同的是,values 会根据 value 的类型进行划分,这里会将一个 id 对应的 values 划分为 vertex 和 edge 集合。
总结一下,本小节将所有 split 解析成了(id vertex)和(id edge),并将这些键值对 shuffle 到了指定的 worker,下面就需要解析 worker 是怎么处理这些键值对的。
3、规约点和边
Graph 中图是以邻接表的形式存储的,因此,内存中的对象组织形式就是,每个点对应一个 vertex 对象,而边作为 vertex 对象的成员变量存在,表示此 vertex 的出边。
因此,我们此阶段要做的工作,就是将从上一节得到的键值对,封装到一个 vertex 对象中,并把此 vertex 对象添加到最终的图中,此 vertex 对象也是计算阶段迭代遍历的vertex对象。
我们用下图表示此阶段的执行过程:

此过程,针对每个 id 汇总后的结果,将上一节中针对此 id 的添加的所有 vertex 和 edge 都封装到一个 vertex 对象中。封装的过程是通过 VertexResolver 接口完成的,此接口我们会提供一个默认实现,用户也可以自定义,根据自己作业的情况进行特殊处理。
针对一个 id 添加的 vertex 和 edge,我们提供的默认实现有如下步骤:
-
检查是否添加了 vertex,没有添加 vertex 或者添加了多个 vertex时报错;
-
检查 vertex 中的 edge是否有重复,如果存在重复则报错;
-
如果添加了 edge,检查 vertex 中的 edge 和添加的 edge 是否有重复,如果存在重复则报错;
-
以上检查通过后,将所有的 edge 都放入 vertex 中,并将此 vertex 添加到最终的图中。 用流程图的形式表述如下:

总结一下,本小节我们将 shuffle 之后的(id vertex)和(id edge)键值对,成功的封装成了最终的 vertex 对象,这些 vertex 对象最终也将参与后续的迭代计算。请注意,对于每个 id,都会经过这个阶段,并不是只有冲突的时候才会这样。
三、编程接口
经过上一章节的介绍,我们已经对整个图数据加载的原理有了初步的认识,下面我们开始介绍主要的接口,从上一章节得知,用户只需要实现 GraphLoader 和 VertexResolver 接口,而 VertexResolver 接口我们提供了默认实现,因此一般情况下,用户只需要自定义 GraphLoader 接口就可以了。
1、GraphLoader
先看一下 GraphLoader 接口的代码:
public abstract class GraphLoader<VERTEX_ID extends WritableComparable VERTEX_VALUE extends Writable EDGE_VALUE extends Writable MESSAGE extends Writable> { public void setup(Configuration conf int workerId TableInfo tableInfo) throws IOException { } public abstract void load(LongWritable recordNum Record record MutationContext<VERTEX_ID VERTEX_VALUE EDGE_VALUE MESSAGE> context) throws IOException;}
首先解释一下四个泛型参数的含义:
-
VERTEX_ID 代表点的 id 的数据类型;
-
VERTEX_VALUE 代表点的值的数据类型;
-
EDGE_VALUE 代表边的值的数据类型;
-
MESSAGE 代表迭代时消息的数据类型; 这些类型都是用户可以自定义的,但是都必须都实现 Writable 接口。
我们现在来看 GraphLoader 的两个方法的含义:
-
setup是 GraphLoader 的配置方法,该方法在每个 GraphLoader 实例只被调用一次,我们会将作业的配置信息,当前 worker 的id,当前输入的 table 或 partiton 信息作为参数传递给 setup,用户可以使用这些参数初始化上下文信息。其中,在 main 方法中配置的信息可以在此处通过 Configuration 拿到,当前输入的表名或分区名可以通过 TableInfo 拿到。
-
load 针对 split 中的每个 record 调用一次,用户可以读取 record 中各列的数据,转换成 vertex 和(或)edge,并通过 MutationContext 接口请求添加到图中。MutationContext接口的方法:
public interface MutationContext<I extends WritableComparable V extends Writable E extends Writable M extends Writable> { public abstract Configuration getConfiguration(); public abstract int getNumWorkers(); public void addVertexRequest(Vertex<I V E M> vertex) throws IOException; public void removeVertexRequest(I vertexId) throws IOException; public abstract void addEdgeRequest(I sourceVertexId Edge<I E> edge) throws IOException; public void removeEdgeRequest(I sourceVertexId I targetVertexId) throws IOException; public abstract Counter getCounter(Enum<?> name); public abstract Counter getCounter(String group String name);}
其中 getConfiguration 方法的返回值与 setup 的 Configuration 参数相同,geNumWorkers获取作业总的 worker 的个数,getCounter 是允许用户自定义 counter 来做一些统计,在作业结束时,这些 counter 可以通过 sdk 被获取到。最重要的是剩余的四个方法,其中 removeVertexRequest 和
RemoveEdgeRequest 方法可以暂时忽略,它们的作用是可以根据输入数据,可以选择去删除一些点和边,在数据载入阶段,这种需求并不常见。
我们重点关注addVertexRequest和addEdgeRequest,这两个方法的作用,就是生成我们之前提到的(id vertex)和(id edge)。addVertexRequest(Vertex vertex)会生成(id vertex)的键值对,id 是 vertex 的 id。addEdgeRequest(I sourceVertexId Edge edge) 会生成(id edge)的键值对,id是边的起始点,edge包含边的终点和值。 >
总结一下,实现 GraphLoader 的目的,就是根据上下文,在 load 方法中,解释 record,并调用 MutationContext 接口,请求将 vertex 和 edge 添加到图中。
请注意,这里的方法名字都带有Request字样,意思就是说调用这些方法,只代表一种请求,最终这些请求是否生效,取决于 VertexResolver 的实现。
2、VertexResolver
在所有的 split 被 GraphLoader 处理结束后,我们会做一次同步,使得所有 worker 统一开始执行 VertexResolver,我们先看一下 VertexResolver的方法:
public abstract class VertexResolver<I extends WritableComparable V extends Writable E extends Writable M extends Writable> { public void configure(Configuration conf) throws IOException { } public abstract Vertex<I V E M> resolve(I vertexId Vertex<I V E M> vertex VertexChanges<I V E M> vertexChanges boolean hasMessages) throws IOException;}
每个 worker 上只会创建一个 VertexResolver的实例,这个实例负责处理属于此 worker 的所有点,即将关于一个 id 的 vertex 和 edge 封装成一个 vertex 对象。
-
configure 方法 VertexResolver 的配置方法,每个实例只会被调用一次,用于获取作业配置信息;
-
resolve 方法针对每个 id 调用一次,用于处理所有关于此 id 的 vertex 和 edge,它的返回值是一个vertex 对象,表示将此 vertex 添加到最终的图中。参数比较复杂,我们展开介绍:
-
vertexId 是当前要处理的 vertex 的 id,也就是之前所说的 key;
-
vertex 是当前已存在的 vertex 对象,在数据载入阶段,这个参数一定为 null;
-
vertexChanges 是关于此 id 所有的变动集合,主要是 GraphLoader 中添加的 vertex 和 edge,也就是之前所说的 values;
-
hasMessages 表示此 id 是否有收到message,在数据载入阶段,这个参数一定为false; 因此,这四个参数中,只需要关心 vertexId 和 VertexChanges 两个参数,而 vertexChanges就是个集合,它来自于 GraphLoader.load方法中,调用 MutationContext.add*Request接口添加的 vertex 和 edge,vertexChanges 内部也按照 vertex 和 edge 划分了不同的子集合,我们先看一下 VertexChanges 接口的方法:
public interface VertexChanges<I extends WritableComparable V extends Writable E extends Writable M extends Writable> { public List<Vertex<I V E M>> getAddedVertexList(); public int getRemovedVertexCount(); public List<Edge<I E>> getAddedEdgeList(); public List<I> getRemovedEdgeList();}
看这个四个方法,是不是和 MutationContext 中的方法相似?是的, MutationContext中的add/remove*Reuqest方法分别与这里的get*List对应,也解释了上一小节所说的。MutationContext 的调用都是些请求,并不一定是最终的 vertex 和 edge,因为它们要在这里进行经过处理才能决定是否真正要添加到最终的图中。
总结一下,VertexResolver 是数据加载的最后一步,它的作用就是构造最终的图结构,构造过程就是将 GraphLoader 里生成的键值对进行封装,使得最终的图结构以一种邻接表的形式存在。
四、举例
我们举两种类型的示例说明图的加载过程。输入数据一般可以划分成边类型和点类型的数据,我们分开举例说明。
1、边类型数据
边类型的数据可以用下面的表格表示:
| SourceVertexID | DestinationVertexID | EdgeValue |
|---|---|---|
| id0 | id1 | 9 |
| id0 | id2 | 5 |
| id2 | id1 | 4 |
每条Record表示图中的一条边的格式,上图表示id0有两条出边,分别指向id1和id2;id2有一条出边,指向id1;id1没有出边。
对应的 GraphLoader 的实现为:
/** * 将Record解释为Edge,此处对于上述第一种情况,每个Record只表示一条Edge。 * <p> * 类似于{@link com.aliyun.odps.mapreduce.Mapper#map} * ,输入Record,生成键值对,此处的键是Vertex的ID, * 值是Edge,通过上下文Context写出,这些键值对会在LoadingVertexResolver出根据Vertex的ID汇总。 * * 注意:此处添加的点或边只是根据Record内容发出的请求,并不是最后参与计算的点或边,只有在随后的{@link VertexResolver} * 中添加的点或边才参与计算。 */ public static class EdgeInputLoader extends GraphLoader<LongWritable LongWritable LongWritable LongWritable> { /** * 配置EdgeInputLoader。 * * @param conf * 作业的配置参数,在main中使用GraphJob配置的,或者在console中set的 * @param workerId * 当前工作的worker的序号,从0开始,可以用于构造唯一的vertex id * @param inputTableInfo * 当前worker载入的输入表信息,可以用于确定当前输入是哪种类型的数据,即Record的格式 */ @Override public void setup(Configuration conf int workerId TableInfo inputTableInfo) { } /** * 根据Record中的内容,解析为对应的边,并请求添加到图中。 * * @param recordNum * 记录序列号,从1开始,每个worker上单独计数 * @param record * 输入表中的记录,三列,分别表示初点、终点、边的权重 * @param context * 上下文,请求将解释后的边添加到图中 */ @Override public void load( LongWritable recordNum Record record MutationContext<LongWritable LongWritable LongWritable LongWritable> context) throws IOException { /** * 1、第一列表示初始点的ID */ LongWritable sourceVertexID = (LongWritable) record.get(0); /** * 2、第二列表示终点的ID */ LongWritable destinationVertexID = (LongWritable) record.get(1); /** * 3、地三列表示边的权重 */ LongWritable edgeValue = (LongWritable) record.get(2); /** * 4、创建边,由终点ID和边的权重组成 */ Edge<LongWritable LongWritable> edge = new Edge<LongWritable LongWritable>( destinationVertexID edgeValue); /** * 5、请求给初始点添加边 */ context.addEdgeRequest(sourceVertexID edge); /** * 6、如果每条Record表示双向边,重复4与5 Edge<LongWritable LongWritable> edge2 = new * Edge<LongWritable LongWritable>( sourceVertexID edgeValue); * context.addEdgeRequest(destinationVertexID edge2); */ } }
对应的 VertexResolver的实现为:
/** * 汇总{@link GraphLoader#load(LongWritable Record MutationContext)}生成的键值对,类似于 * {@link com.aliyun.odps.mapreduce.Reducer#reduce}。对于唯一的Vertex ID,所有关于这个ID上 * 添加\删除、点\边的行为都会放在{@link VertexChanges}中。 * * 注意:此处并不只针对load方法中添加的有冲突的点或边才调用(冲突是指添加多个相同Vertex对象,添加重复边等), * 所有在load方法中请求生成的ID都会在此处被调用。 */ public static class EdgeResolver extends VertexResolver<LongWritable LongWritable LongWritable LongWritable> { /** * 处理关于一个ID的添加或删除、点或边的请求。 * * <p> * {@link VertexChanges}有四个接口,分别与{@link MutationContext}的四个接口对应: * <ul> * <li>{@link VertexChanges#getAddedVertexList()}与 * {@link MutationContext#addVertexRequest(Vertex)}对应, * 在load方法中,请求添加的ID相同的Vertex对象,会被汇总在返回的List中 * <li>{@link VertexChanges#getAddedEdgeList()}与 * {@link MutationContext#addEdgeRequest(WritableComparable Edge)} * 对应,请求添加的初始点ID相同的Edge对象,会被汇总在返回的List中 * <li>{@link VertexChanges#getRemovedVertexCount()}与 * {@link MutationContext#removeVertexRequest(WritableComparable)} * 对应,请求删除的ID相同的Vertex,汇总的请求删除的次数作为返回值 * <li>{@link VertexChanges#getRemovedEdgeList()}与 * {@link MutationContext#removeEdgeRequest(WritableComparable WritableComparable)} * 对应,请求删除的初始点ID相同的Edge对象,会被汇总在返回的List中 * <ul> * * <p> * 用户通过处理关于这个ID的变化,通过返回值声明此ID是否参与计算,如果返回的{@link Vertex}不为null, * 则此ID会参与随后的计算,如果返回null,则不会参与计算。 * * @param vertexId * 请求添加的点的ID,或请求添加的边的初点ID * @param vertex * 已存在的Vertex对象,数据载入阶段,始终为null * @param vertexChanges * 此ID上的请求添加\删除、点\边的集合 * @param hasMessages * 此ID是否有输入消息,数据载入阶段,始终为false */ @Override public Vertex<LongWritable LongWritable LongWritable LongWritable> resolve( LongWritable vertexId Vertex<LongWritable LongWritable LongWritable LongWritable> vertex VertexChanges<LongWritable LongWritable LongWritable LongWritable> vertexChanges boolean hasMessages) throws IOException { /** * 1、生成Vertex对象,作为参与计算的点。 */ EdgeVertex computeVertex = new EdgeVertex(); computeVertex.setId(vertexId); /** * 2、将请求给此点添加的边,添加到Vertex对象中,如果数据有重复的可能,根据算法需要决定是否去重。 */ if (vertexChanges.getAddedEdgeList() != null) { for (Edge<LongWritable LongWritable> edge : vertexChanges .getAddedEdgeList()) { computeVertex.addEdge(edge.getDestVertexId() edge.getValue()); } } /** * 3、将Vertex对象返回,添加到最终的图中参与计算。 */ return computeVertex; } }
2、点类型数据
我们分析一个多路输入的例子。Graph作业指定两张表作为输入,一张是边类型的数据,格式如1中所示,另一张是点类型的数据,格式可以用下面的表格表示:
| VertexID | VertexValue |
|---|---|
| id0 | 9 |
| id1 | 7 |
| id2 | 8 |
表示有三个点,id分别是id0,id1,id2,对应的点的值分别是9,7,8。
对应的 GraphLoader 的实现为:
/** * 将Record解释为Vertex和Edge,每个Record根据其来源,表示一个Vertex或者一条Edge。 * <p> * 类似于{@link com.aliyun.odps.mapreduce.Mapper#map} * ,输入Record,生成键值对,此处的键是Vertex的ID, * 值是Vertex或Edge,通过上下文Context写出,这些键值对会在LoadingVertexResolver出根据Vertex的ID汇总。 * * 注意:此处添加的点或边只是根据Record内容发出的请求,并不是最后参与计算的点或边,只有在随后的{@link VertexResolver} * 中添加的点或边才参与计算。 */ public static class VertexInputLoader extends GraphLoader<LongWritable LongWritable LongWritable LongWritable> { private boolean isEdgeData; /** * 配置VertexInputLoader。 * * @param conf * 作业的配置参数,在main中使用GraphJob配置的,或者在console中set的 * @param workerId * 当前工作的worker的序号,从0开始,可以用于构造唯一的vertex id * @param inputTableInfo * 当前worker载入的输入表信息,可以用于确定当前输入是哪种类型的数据,即Record的格式 */ @Override public void setup(Configuration conf int workerId TableInfo inputTableInfo) { isEdgeData = conf.get(EDGE_TABLE).equals(inputTableInfo.getTableName()); } /** * 根据Record中的内容,解析为对应的边,并请求添加到图中。 * * @param recordNum * 记录序列号,从1开始,每个worker上单独计数 * @param record * 输入表中的记录,三列,分别表示初点、终点、边的权重 * @param context * 上下文,请求将解释后的边添加到图中 */ @Override public void load( LongWritable recordNum Record record MutationContext<LongWritable LongWritable LongWritable LongWritable> context) throws IOException { if (isEdgeData) { /** * 数据来源于存储边信息的表。 * * 1、第一列表示初始点的ID */ LongWritable sourceVertexID = (LongWritable) record.get(0); /** * 2、第二列表示终点的ID */ LongWritable destinationVertexID = (LongWritable) record.get(1); /** * 3、地三列表示边的权重 */ LongWritable edgeValue = (LongWritable) record.get(2); /** * 4、创建边,由终点ID和边的权重组成 */ Edge<LongWritable LongWritable> edge = new Edge<LongWritable LongWritable>( destinationVertexID edgeValue); /** * 5、请求给初始点添加边 */ context.addEdgeRequest(sourceVertexID edge); /** * 6、如果每条Record表示双向边,重复4与5 Edge<LongWritable LongWritable> edge2 = new * Edge<LongWritable LongWritable>( sourceVertexID edgeValue); * context.addEdgeRequest(destinationVertexID edge2); */ } else { /** * 数据来源于存储点信息的表。 * * 1、第一列表示点的ID */ LongWritable vertexID = (LongWritable) record.get(0); /** * 2、第二列表示点的值 */ LongWritable vertexValue = (LongWritable) record.get(1); /** * 3、创建点,由点的ID和点的值组成 */ MyVertex vertex = new MyVertex(); /** * 4、初始化点 */ vertex.setId(vertexID); vertex.setValue(vertexValue); /** * 5、请求添加点 */ context.addVertexRequest(vertex); } } }
对应的 VertexResolver 的实现为:
/** * 汇总{@link GraphLoader#load(LongWritable Record MutationContext)}生成的键值对,类似于 * {@link com.aliyun.odps.mapreduce.Reducer#reduce}。对于唯一的Vertex ID,所有关于这个ID上 * 添加\删除、点\边的行为都会放在{@link VertexChanges}中。 * * 注意:此处并不只针对load方法中添加的有冲突的点或边才调用(冲突是指添加多个相同Vertex对象,添加重复边等), * 所有在load方法中请求生成的ID都会在此处被调用。 */ public static class LoadingResolver extends VertexResolver<LongWritable LongWritable LongWritable LongWritable> { /** * 处理关于一个ID的添加或删除、点或边的请求。 * * <p> * {@link VertexChanges}有四个接口,分别与{@link MutationContext}的四个接口对应: * <ul> * <li>{@link VertexChanges#getAddedVertexList()}与 * {@link MutationContext#addVertexRequest(Vertex)}对应, * 在load方法中,请求添加的ID相同的Vertex对象,会被汇总在返回的List中 * <li>{@link VertexChanges#getAddedEdgeList()}与 * {@link MutationContext#addEdgeRequest(WritableComparable Edge)} * 对应,请求添加的初始点ID相同的Edge对象,会被汇总在返回的List中 * <li>{@link VertexChanges#getRemovedVertexCount()}与 * {@link MutationContext#removeVertexRequest(WritableComparable)} * 对应,请求删除的ID相同的Vertex,汇总的请求删除的次数作为返回值 * <li>{@link VertexChanges#getRemovedEdgeList()}与 * {@link MutationContext#removeEdgeRequest(WritableComparable WritableComparable)} * 对应,请求删除的初始点ID相同的Edge对象,会被汇总在返回的List中 * <ul> * * <p> * 用户通过处理关于这个ID的变化,通过返回值声明此ID是否参与计算,如果返回的{@link Vertex}不为null, * 则此ID会参与随后的计算,如果返回null,则不会参与计算。 * * @param vertexId * 请求添加的点的ID,或请求添加的边的初点ID * @param vertex * 已存在的Vertex对象,数据载入阶段,始终为null * @param vertexChanges * 此ID上的请求添加\删除、点\边的集合 * @param hasMessages * 此ID是否有输入消息,数据载入阶段,始终为false */ @Override public Vertex<LongWritable LongWritable LongWritable LongWritable> resolve( LongWritable vertexId Vertex<LongWritable LongWritable LongWritable LongWritable> vertex VertexChanges<LongWritable LongWritable LongWritable LongWritable> vertexChanges boolean hasMessages) throws IOException { /** * 1、获取Vertex对象,作为参与计算的点。 */ MyVertex computeVertex = null; if (vertexChanges.getAddedVertexList() == null || vertexChanges.getAddedVertexList().isEmpty()) { computeVertex = new MyVertex(); computeVertex.setId(vertexId); } else { /** * 此处假设存储点信息的表中,每个Record表示唯一的点。 */ computeVertex = (MyVertex) vertexChanges.getAddedVertexList().get(0); } /** * 2、将请求给此点添加的边,添加到Vertex对象中,如果数据有重复的可能,根据算法需要决定是否去重。 */ if (vertexChanges.getAddedEdgeList() != null) { for (Edge<LongWritable LongWritable> edge : vertexChanges .getAddedEdgeList()) { computeVertex.addEdge(edge.getDestVertexId() edge.getValue()); } } /** * 3、将Vertex对象返回,添加到最终的图中参与计算。 */ return computeVertex; } }



